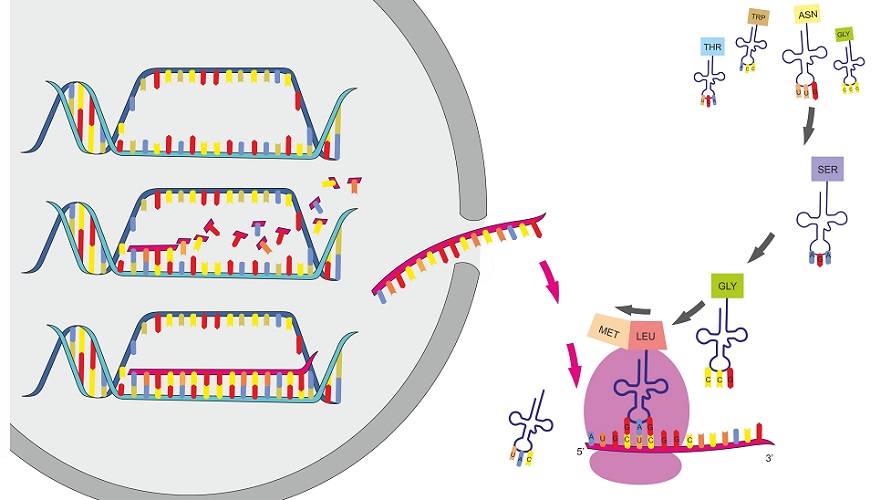
Protein synthesis is one of the most fundamental biological processes by
which individual cells build their specific proteins. Within the process are
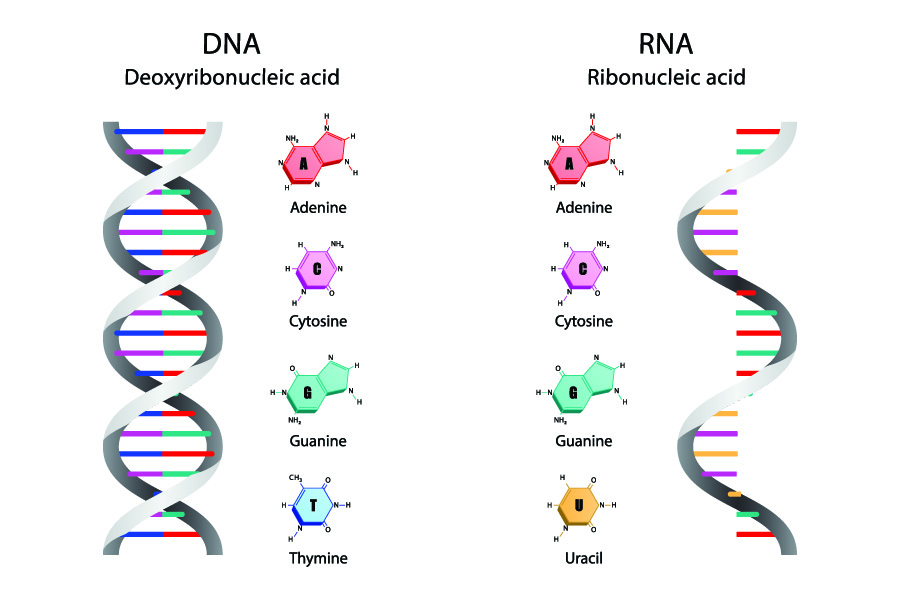
involved both DNA (deoxyribonucleic acid) and different in their function
ribonucleic acids (RNA). The process is initiated in the cell’s nucleus, where
specific enzymes unwind the needed section of DNA, which makes the DNA in this
region accessible and a RNA copy can be made. This RNA molecule then moves
from the nucleus to the cell cytoplasm, where the actual the process of
protein synthesis take place. (this page is way under construction still)
Protein synthesis is process in which polypeptide chains are formed from coded combinations of
single amino acids inside the cell. The synthesis of new polypeptides requires a coded sequence,
enzymes, and messenger, ribosomal, and transfer ribonucleic
acids (RNAs). Protein synthesis takes place within the nucleus
and ribosomes of a cell and is regulated by DNA and RNA.
Protein synthesis
Protein Synthesis Steps
Protein synthesis steps are twofold. Firstly, the code for a
protein (a chain of amino acids in a specific order) must be
copied from the genetic information contained within a cell’s
DNA. This initial protein synthesis step is known as transcription.
Transcription produces an exact copy of a section of DNA. This
copy is known as messenger RNA (mRNA) which must then be transported outside of the cell nucleus before the next step of protein synthesis can begin.
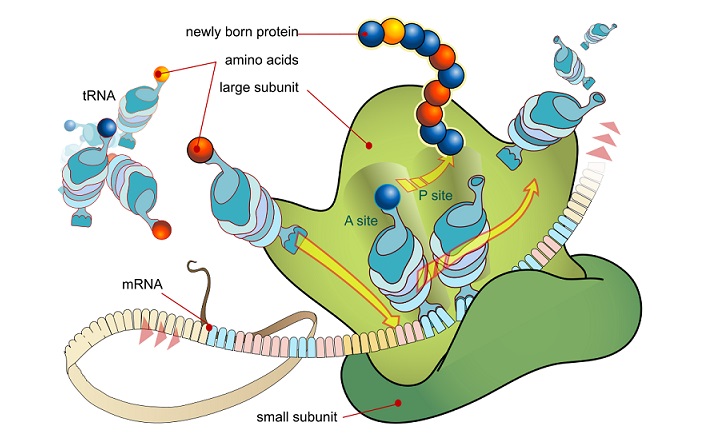
The second protein synthesis step is translation. Translation occurs within a cell organelle called a ribosome. Messenger RNA makes its way to and connects with the ribosome
under the influence of ribosomal RNA and enzymes. Transfer RNA (tRNA) is a molecule that carries a single amino acid and a coded sequence
that acts like a key. This key fits into a specific sequence of
three codes on the mRNA, bringing the correct amino acid into
place. Each set of three mRNA nitrogenous bases is called a
codon.
Translation and transcription will be explained in much more
detail further on. In order to keep protein synthesis simple, we
first need to know the basics.
Polypeptides and Proteins
The result of protein synthesis is a chain of amino acids that
have been attached, link by link, in a specific order. This
chain is called a polymer or polypeptide and is constructed
according to a DNA-based code. You can picture a polypeptide
chain as a string of beads, with each bead playing the part of
an amino acid. The order in which the beads are strung are
copied from instructions in our DNA.
Like beads on a necklace
When speaking of protein synthesis it is important to make a
distinction between polypeptide chains and proteins. All
proteins are polypeptides but not all polypeptides are proteins;
however, both proteins and polypeptides are composed of amino
acid monomers.
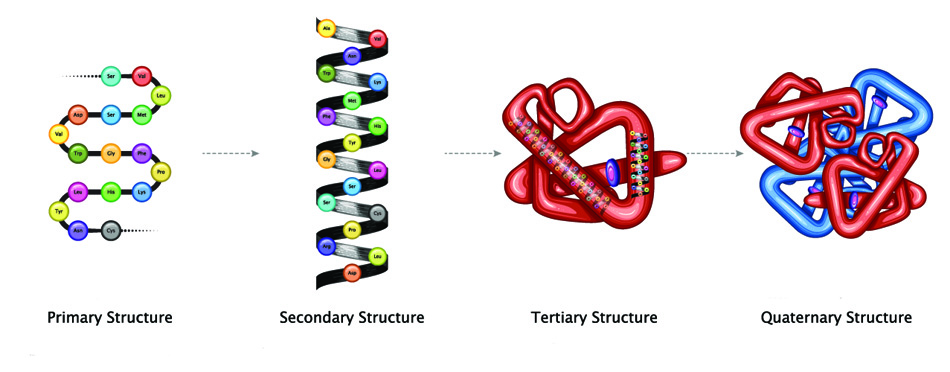
The difference between a protein and a polypeptide is the form.
Smaller chains of amino acids – usually less than forty – remain
as single-chain strands and are called polypeptides. Larger
chains must package themselves more tightly; they fold into
fixed structures – secondary, tertiary, and quaternary. When a
polypeptide chain folds, it is called a protein.
Polypeptide chains are formed during the translation process of
protein synthesis. These polypeptides may or may not fold into
proteins at a later stage. However, the term ‘protein synthesis’
is used even in the scientific community and is not incorrect.
Understanding protein synthesis is easy when we imagine our DNA
as a recipe book. This book lists the instructions that show a
cell how to make every tiny part of every system, organ, and tissuewithin our bodies. All of these individual parts are
polypeptides. From the keratin in your hair and fingernails to
the hormones that run through your bloodstream, polypeptides and
proteins are the foundation stones of every structure. Our DNA
does not code for lipids or carbohydrates – it only codes for
polypeptides.
The enzyme RNA polymerase opens the DNA recipe book that sits inside the cell
nucleus. It uses certain pieces of code as bookmarks to find the
right page. This recipe book is written in a foreign language –
mRNA copies what is written without understanding it. The
recipes are translated into a language that other molecules can
decipher at a later stage. The translators are ribosomes and
tRNA. They read the recipe and can collect the right ingredients
and, in the correct order, make the finished polypeptide
product.
The protein recipe must first be translated
DNA Sequences
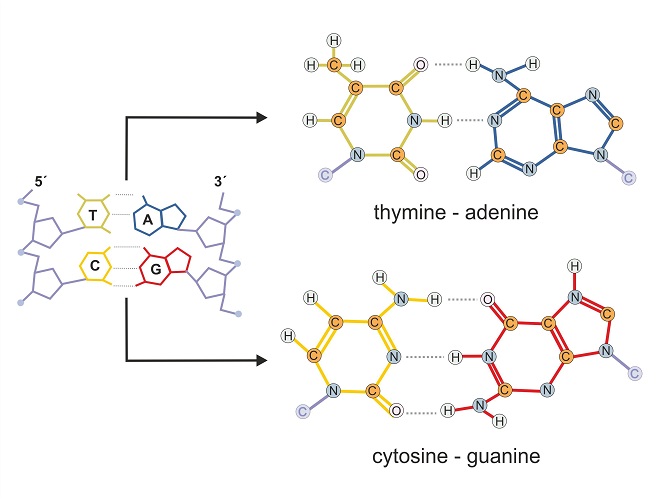
In the nucleus, two strands of DNA are held together by
nitrogenous bases (also called nucleobases or bases). Four bases
– cytosine, guanine, adenine, and thymine – form the letters of the words in the DNA recipe book.
One strand of DNA holds the original code. If the instructions
of this code are carefully followed, a specific correct
polypeptide can be assembled outside the nucleus. The second DNA
strand – the template strand – is a mirror image of the original
strand. It must be a mirror image as nucleobases can only attach
to complementary partners. For example, cytosine only ever pairs
with guanine and thymine only pairs with adenine.
Matched nucleobase pairs
You will probably have seen codes such as CTA, ATA, TAA, and CCC
in various biology textbooks. If these are the codons (sets of
three bases) of the original strand of DNA, the template strand
will attach to these using their partners. So using the given
examples, template DNA will attach to the original DNA strand
using GAT, TAT, ATT, and GGG.
Messenger RNA then copies the template strand. This means it
ends up creating an exact copy of the original strand. The only
difference is that mRNA replaces thymine with a base called
uracil. The mRNA copy of the template strand using the given
examples would read CUA, AUA, UAA, and CCC.
Bases in DNA and RNA
These codes can be read by transfer RNA outside the nucleus; the
recipe can be understood by a molecule that does not fully
understand the language used in the original (it does not
understand thymine, only uracil). Transfer RNA helps to bring
the right parts to the assembly line of the ribosome. There, a
protein chain is constructed that matches the instructions in
the original DNA strand.
Protein Synthesis Contributors
To make the copied stretch of code (transcription) we need
enzymes called RNA polymerases. These enzymes gather
free-floating messenger RNA (mRNA) molecules inside the nucleus
and assemble them to form the letters of the code. Each letter
of DNA code has its own key and each new letter formed by mRNA
carries a lock that suits this key, a little like tRNA.
Notice that we are talking about letters. This is important.
Inside the nucleus, the DNA code is not understood, simply
copied down – transcribed. Understanding the code by spelling
out the words formed by these letters – translating –
happens at a later stage.
Copying the details without understanding them – transcription
RNA polymerase must find and bring over the appropriate mRNA
molecule for each nitrogenous base on the template strand. Selected mRNA molecules link
together to form a chain of letters. Eventually, these letters
will spell out the equivalent of a phrase. Each phrase
represents a specific (polypeptide) product. If the recipe is
not exactly followed, the final product might be completely
different or not work as well as it should.
Messenger RNA has now become the code. It travels to the next
group of important contributors that work as manufacturing
plants. Ribosomes are found outside the cell nucleus, either in
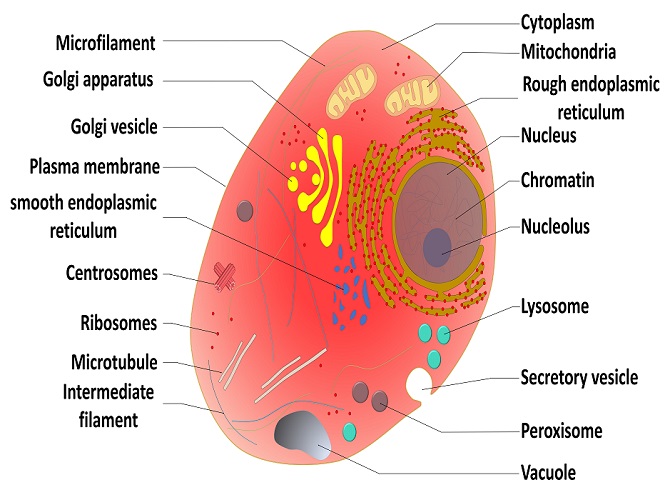
the cell cytoplasm or attached to the rough endoplasmic reticulum; it is ribosomes that make the endoplasmic reticulum ‘rough’.
A ribosome is split into two parts and the strand of mRNA runs
through it like ribbon through an old-fashioned typewriter. The
ribosome recognizes and connects to a special code at the start
of the translated phrase – the start codon. Transfer RNA molecules enter the ribosome, bringing with them
individual ingredients. As with all of these processes, enzymes
are required to make the connections.
Old typewriters help us understand how translation works
If each mRNA codon has a lock, tRNA possesses the keys. The tRNA
key for an mRNA codon is called an anticodon. When a tRNA molecule holds the key that matches a
three-nucleobase code it can open the door, drop off its load
(an amino acid), and leave the ribosome factory to collect
another amino acid load. This will always be the same type of
amino acid as the anticodon.
Messenger RNA shifts along the ribosome as if on a conveyor
belt. At the next codon another tRNA molecule (with the right
key) brings the next amino acid. This amino acid bonds to the
previous one. A chain of bonded amino acids begins to form– a
polypeptide chain. When completed, this polypeptide chain is an
accurate final product manufactured according to the
instructions in the DNA recipe book. Not a pie or a cake but a
polypeptide chain.
The finished product, ready for use
The end of the mRNA code translation process is signaled by
a stop codon. Start and stop codons do not code for amino acids but tell
the tRNA and ribosome where a polypeptide chain should begin and
end.
The finished product – the newly synthesized polypeptide – is
released into the cytoplasm. From there it can travel to
wherever it is needed.
Site of Protein Synthesis
The site of protein synthesis is twofold. Transcription (copying
the code) occurs within the cell nucleus where DNA is located.
Once the mRNA copy of a small section of DNA has been made it
travels through the nuclear pores and into the cell cytoplasm.
In the cytoplasm, the strand of mRNA will move towards a free
ribosome or one attached to the rough endoplasmic reticulum.
Then the next step of protein synthesis – translation – can
begin.
New Roles for Ribosomes
The average mammalian cell contains more than ten million
ribosomes. Cancer cells can produce up to 7,500 ribosomal
subunits (small and large) every minute. As a
polypeptide-producing factory, the existence, development, and
function of every living organismdepends on the ribosome.
Ribosome function
It was previously thought that eukaryotic ribosomes only played
effector roles in protein synthesis (caused an effect – a new
protein). However, recent research now shows that ribosomes also
regulate the translation process. They play a part in deciding
which proteins are manufactured and in what quantities. The
success and results of translation depend on more than the
availability of free amino acids and enzymes – they also
depend on the quality of the ribosomes.
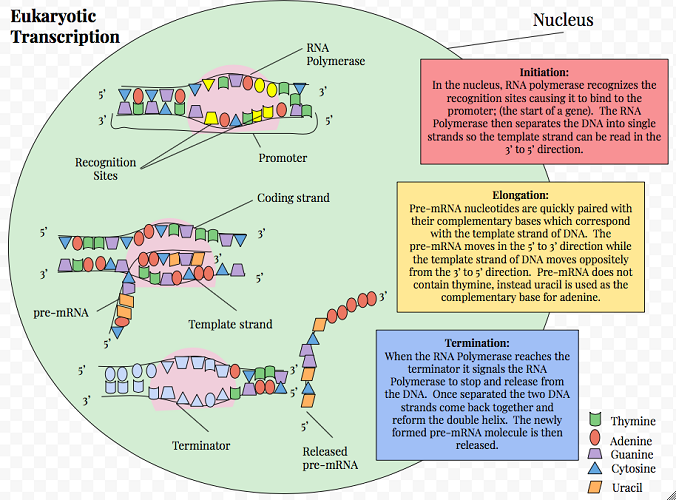
Transcription in Protein Synthesis
The transcription process is the first step of protein
synthesis. This step transfers genetic information from DNA to
the ribosomes of the cytoplasm or rough endoplasmic reticulum.
Transcription is divided into three phases: initiation,
elongation and termination.
Transcription within the nucleus, translation without
Initiation
Initiation requires two special protein groups. The first group
is transcription factors – these recognize promoter sequences in
the DNA. A promoter sequence is a section of code found at the
start of a single gene that shows where the copying process should begin and in
which direction this code should be read. A promoter works a
little like the start codon on mRNA.
The second protein group necessary for transcription initiation
consists of DNA-dependent RNA polymerases (RNAPs). An RNA
polymerase molecule binds to the promoter. Once this connection
has been made, the double-stranded DNA unwinds and opens
(unzips).
RNA polymerase = zipper
Connected bases keep the two strands of DNA in a double-helix
form. When the two strands unzip, the individual and now
unpartnered bases are left exposed. The unzipping process is
repeated along the stretch of DNA by RNAPs until the
transcription stop point or terminator is reached. Intitiation,
therefore, involves the recognition of a promotor sequence and
the unzipping of a section of DNA under the influence of
transcription factors and RNA polymerases.
RNA polymerase separates the DNA bases
Elongation
The next phase in the transcription process is elongation. With
the coded sequence exposed, RNAPs can read each individual
adenine, guanine, cytosine, or thymine base on the template
strand and connect the correct partner base to it. It is
important to remember that RNA is unable to replicate thymine
and replaces this with the nucleobase known as uracil.
If, for example, a short DNA sequence on the template strand is
represented by C-A-G-T-T-A or
cytosine-adenine-guanine-thymine-thymine-adenine, RNAP will
connect the correct partner bases obtained from populations of
free-floating bases within the nucleus. In this example, RNA
polymerase will attach a guanine base to cytosine, uracil to
adenine, cytosine to guanine, and adenine to thymine to form a
strand of messenger RNA with the coded nitrogenous base sequence
G-U-C-A-A-U. This process repeats until the RNAP enzyme detects
a sequence of genetic code that terminates it – the terminator.
The phases of transcription
Termination
When the RNAPs detect a terminator sequence, the final phase of
transcription – termination – takes place. The string of RNAPs
disconnect from the DNA and the result is a strand of messenger
RNA. This mRNA carries the code that will eventually instruct
tRNA which amino acids to bring to a ribosome.
Messenger RNA leaves the nucleus via nuclear pores primarily
through diffusion but sometimes needs help from transporter enzymes and ATP
to reach its destination.
Translation Process in Protein Synthesis
During the translation process, the small and large subunits of
a ribosome close over a strand of mRNA, trapping it loosely
inside. Ribosomes arrange the strand into codons or sets of
three nitrogenous base letters. This is because the code for a
single amino acid – the most basic form of a protein – is a
three-letter nucleobase code.
As ribosomes recognize parts of code, we can say they understand
it. The jumble of copied letters made during the transcription
phase can be read and understood in the translation phase.
Only during translation can the code be understood
For example, GGU, GGC, GGA, and GGG code for the amino acid
known as glycine. Most amino acids have multiple codes as this
lowers the chance of mistakes – if RNA polymerase accidently
connects adenine instead of cytosine to GG, it doesn’t matter.
Both GGC and GGA code for the same amino acid. You can see a list of mRNA codons for the twenty non-essential amino
acids here.
There is only one start codon code – AUG. Three codons –
TAA, TAG, and TGA – represent stop codons. Neither start nor
stop codons match the code for an amino acid; they are
non-coding. The single start and three stop codons are clearly
marked on this codon wheel.
The codon wheel
When a codon becomes visible – once the previous codon has been
linked to an amino acid – a section of a transfer RNA molecule
fits into the mRNA codon. This ‘key’ is called the anticodon.
Transfer RNA has two roles – to attach to an amino acid outside
of the ribosome and to deploy this amino acid at the right time
and in the right position on an mRNA strand within the ribosome.
Tens to thousands of transfer RNA molecules produce a
polypeptide chain. Titin or connectin is the largest protein
molecule and contains around 33,000 amino acids. The smallest
functional polypeptide is glutathione – just three amino acids.
To produce glutathione, first the ribosome and tRNA must read
the start codon (three bases), then read the first
protein-coding codon (three bases), the second (three bases),
the third (three bases), and the stop codon (three bases). The
coding DNA and mRNA recipes (sequences) for glutathione contain
nine bases. There may or may not be additional sections of
non-coding DNA within this recipe. Non-coding sequences do not produce amino acids.
As with the process of transcription, translation within the
ribosome is also split into the three stages of initiation,
elongation, and termination.
Time to make sense of the code
Initiation involves the recognition by the ribosome of the mRNA
start codon. Elongation refers to the process whereby the
ribosome moves along the mRNA transcript, recognizing and
exposing individual codons so that tRNA can bring the right
amino acids. The anticodon arm of tRNA attaches to the
appropriate mRNA codon under the influence of ribosomal enzymes.
Finally, termination occurs when the ribosome recognizes the
mRNA stop codon; the completed polypeptide chain is then
released into the cytoplasm. It is sent wherever it is needed –
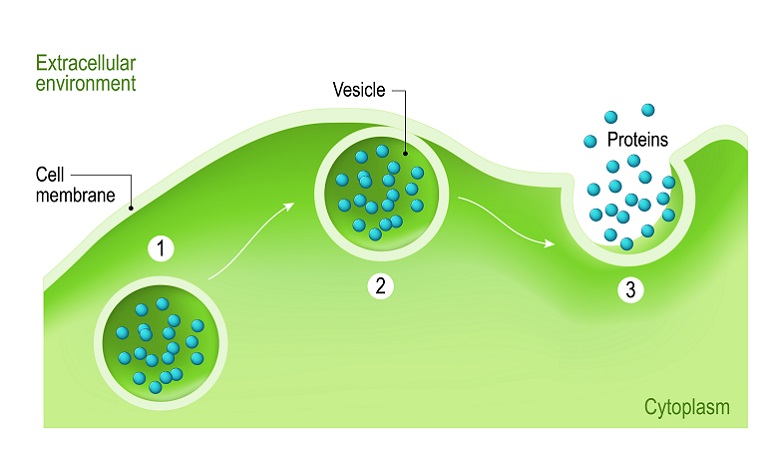
inside the cell or to other tissues, exiting the cell membrane via exocytosis.
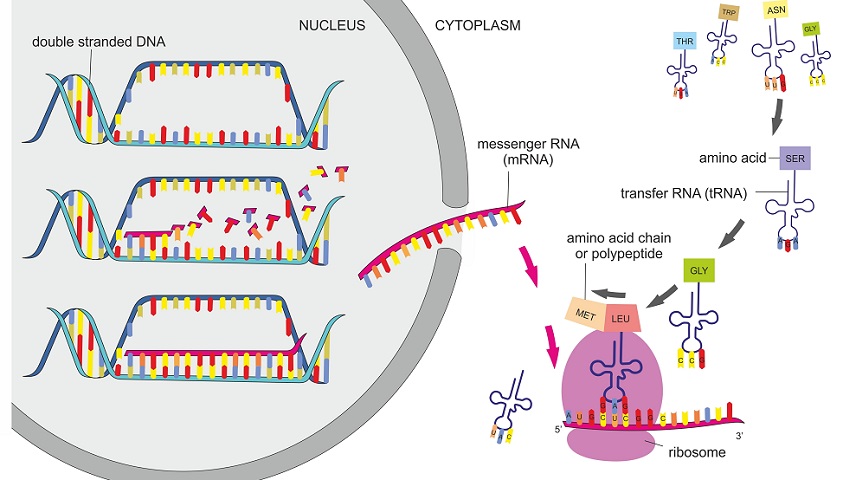
This amazing artwork shows a process that takes place
in the cells of all living things: the production
of proteins. This process is called protein synthesis, and itactually consists of two
processes — transcription and translation. In eukaryotic cells, transcription takes place in the nucleus. During transcription, DNA is used as a template to make a molecule of messenger RNA (mRNA). The molecule of mRNA then leaves the nucleus and goes to a ribosome in the cytoplasm, where translation occurs. During translation,
the genetic code in mRNA is read and used to make a protein. These
two processes are summed up by the central dogma of molecular biology: DNA → RNA → Protein.
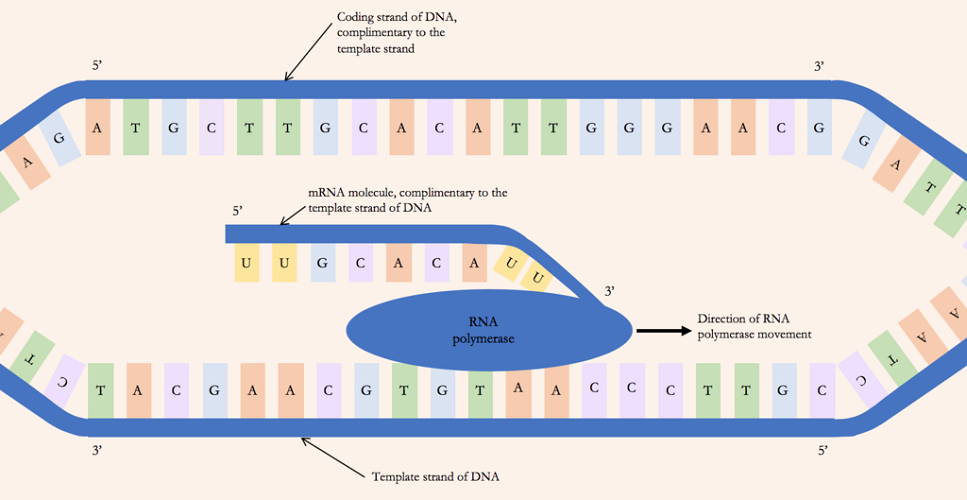
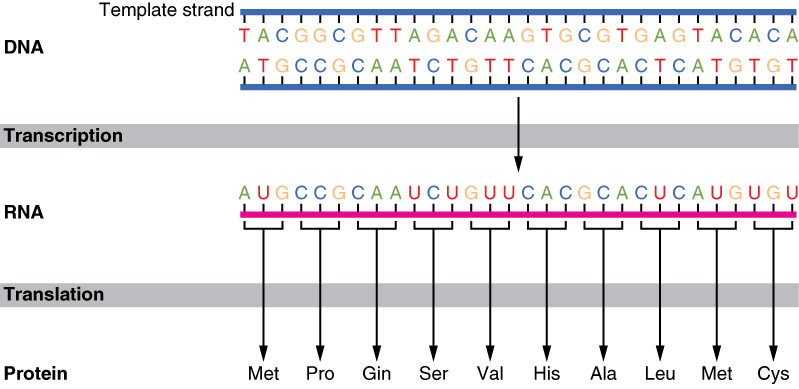
Transcription
Transcription is the first part
of the central dogma of molecular biology: DNA → RNA. It is the transfer of genetic instructions in DNA to
mRNA. During transcription, a strand of mRNA is
made to complement a strand of DNA. You can
see how this happens in the diagram below.
Overview of Transcription. Transcription uses the
sequence of bases in a strand of DNA to make a
complementary strand of mRNA. Triplets are groups of
three successive nucleotide bases in DNA. Codons are
complementary groups of bases in mRNA.
Steps of Transcription
Transcription takes place in three steps: initiation, elongation, and termination. The steps are illustrated in the figure below.
Initiation is the beginning of
transcription. It occurs when the enzymeRNA polymerase binds to a region of a genecalled the promoter. This
signals the DNA to unwind so the enzyme can “read”
the bases in one of the DNA strands. The enzyme is ready
to make a strand of mRNA with a complementary sequence
of bases.
Elongation is the addition
of nucleotides to the mRNA strand.
Termination is the ending of
transcription. The mRNA strand is complete, and it
detaches from DNA.
Steps of Transcription. Transcription occurs in
three steps: initiation, elongation, and
termination.
Processing mRNA
In eukaryotes, the new mRNA is not yet ready for translation. At
this stage, it is called pre-mRNA, and it must go
through more processing before it leaves the nucleus as
mature mRNA. The processing may include splicing, editing, and polyadenylation. These processes modify the mRNA in various ways. Such
modifications allow a single gene to be used to make
more than one protein.
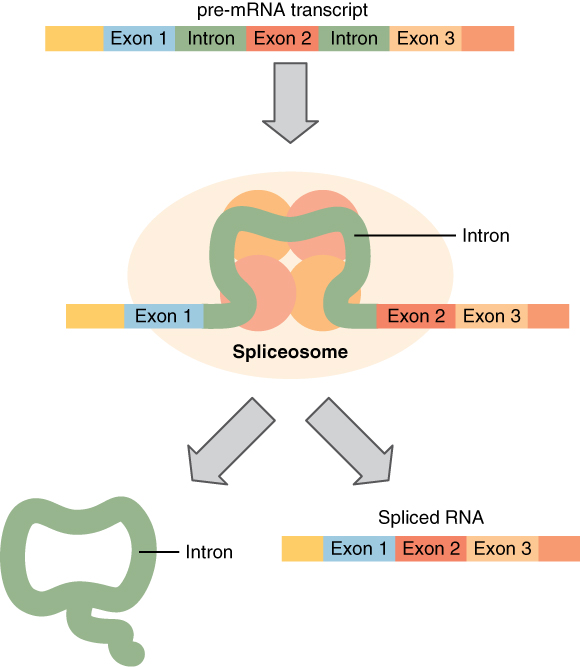
Splicing removes introns from
mRNA, as shown in the diagram below. Introns are regions
that do not code for the protein. The remaining mRNA
consists only of regions
called exons that do code
for the protein. The ribonucleoproteins in the
diagram are small proteins in the nucleus that
contain RNA and are needed for the splicing
process.
Editing changes some of the
nucleotides in mRNA. For example, a human protein
called APOB, which helps transport lipids in the blood, has two different forms because of editing. One
form is smaller than the other because editing adds
an earlier stop signal in mRNA.
Polyadenylation adds a “tail”
to the mRNA. The tail consists of a string of As
(adenine bases). It signals the end of mRNA. It is
also involved in exporting mRNA from the nucleus,
and it protects mRNA from enzymes that might break
it down.
Translation is the second part of
the central dogma of molecular biology: RNA → Protein. It is the process in which the genetic code in mRNA
is read to make a protein. Translation is illustrated in
the diagram below. After mRNA leaves the nucleus, it moves to a
ribosome, which consists of rRNA and proteins. The ribosome reads the sequence
of codons in mRNA, and molecules of tRNA bring amino acids to the ribosome in the correct sequence.
To understand the role of tRNA, you need to know more
about its structure. Each tRNA molecule has
an anticodon for the amino acid it carries.
An anticodon is complementary
to the codon for an amino acid. For example, the amino
acid lysine has the codon AAG, so the anticodon is UUC.
Therefore, lysine would be carried by a tRNA molecule
with the anticodon UUC. Wherever the codon AAG appears
in mRNA, a UUC anticodon of tRNA temporarily binds.
While bound to mRNA, tRNA gives up its amino acid. With
the help of rRNA, bonds form between the amino acids as
they are brought one by one to the ribosome, creating
a polypeptide chain. The chain of amino acids keeps growing
until a stop codon is reached.
Translation. Translation of the codons in mRNA to a
chain of amino acids occurs at a ribosome. Find the
different types of RNA in the diagram. What are
their roles in translation?
What Happens Next?
After a polypeptide chain is synthesized, it may
undergo additional processes. For example, it may assume
a folded shape due to interactions between its
amino acids. It may also bind with other polypeptides or
with different types of molecules, such as lipids
or carbohydrates. Many proteins travel to the Golgi apparatus within the cytoplasm to be modified for the
specific job they will do.
Summary
Protein synthesis is the process in which cells
make proteins. It occurs in two stages:
transcription and translation.
Transcription is the transfer of genetic
instructions in DNA to mRNA in the nucleus. It
includes three steps: initiation, elongation, and
termination. After the mRNA is processed, it carries
the instructions to a ribosome in the
cytoplasm.
Translation occurs at the ribosome, which consists
of rRNA and proteins. In translation, the
instructions in mRNA are read, and tRNA brings the
correct sequence of amino acids to the ribosome.
Then, rRNA helps bonds form between the amino acids,
producing a polypeptide chain.
After a polypeptide chain is synthesized, it may
undergo additional processing to form the finished
protein.
Review
1. Relate protein synthesis and its two major phases to
the central dogma of molecular biology.
2. Identify the steps of transcription, and summarize
what happens during each step.
3. Explain how mRNA is processed before it leaves the
nucleus.
4. Describe what happens during the translation phase
of protein synthesis.
5. What additional processes might a
polypeptide chain undergo after it is synthesized?
6. Where does transcription take place in
eukaryotes?
7. Where does translation take place?
8. Which type of RNA (mRNA, rRNA, or tRNA) best fits
each of the statements below? Choose only one type for
each.
a. contains the codons
b. contains the anticodons
c. makes up the ribosome, along with proteins
9. If the DNA has a triplet code of CAG in one strand
(the strand used as a template for
transcription)...
a. What is the complementary sequence on the other DNA
strand?
b. What is the complementary sequence in the mRNA? What
is this sequence called?
c. What is the resulting sequence in the tRNA? What is
this sequence called? What do you notice about this
sequence compared to the original DNA triplet on the
template strand?
10. The promoter is a region located in the:
a. DNA
b. mRNA
c. tRNA
d. both A and B
11. True or False: Introns in mRNA
bind to tRNA at the ribosome.
12. True or False: tRNAs can be
thought of as the link between amino acids and codons in
the mRNA.
Explore More
Messenger RNA molecules are "spliced" in order to
create the mRNA involved in protein synthesis. Learn the
process here:
Explain how the genetic code stored within DNA determines the protein
that will form
Describe the process of transcription
Describe the process of translation
Discuss the function of ribosomes
It was mentioned earlier that DNA provides a “blueprint” for the cell
structure and physiology. This refers to the fact that DNA contains the
information necessary for the cell to build one very important type of
molecule: the protein. Most structural components of the cell are made up,
at least in part, by proteins and virtually all the functions that a cell
carries out are completed with the help of proteins. One of the most
important classes of proteins is enzymes, which help speed up necessary
biochemical reactions that take place inside the cell. Some of these
critical biochemical reactions include building larger molecules from
smaller components (such as occurs during DNA replication or synthesis of
microtubules) and breaking down larger molecules into smaller components
(such as when harvesting chemical energy from nutrient molecules).
Whatever the cellular process may be, it is almost sure to involve
proteins. Just as the cell’s genome describes its full complement of DNA,
a cell’s proteome is its full complement of proteins. Protein synthesis begins with
genes. A gene is a functional segment of DNA that provides the genetic
information necessary to build a protein. Each particular gene provides
the code necessary to construct a particular protein. Gene expression, which transforms the information coded in a gene to a final gene
product, ultimately dictates the structure and function of a cell by
determining which proteins are made.
The interpretation of genes works in the following way. Recall that
proteins are polymers, or chains, of many amino acid building blocks. The
sequence of bases in a gene (that is, its sequence of A, T, C, G
nucleotides) translates to an amino acid sequence. A triplet is a section of three DNA bases in a row that codes for a specific
amino acid. Similar to the way in which the three-letter code d-o-g signals the image of a dog, the three-letter DNA base code signals
the use of a particular amino acid. For example, the DNA triplet CAC
(cytosine, adenine, and cytosine) specifies the amino acid valine.
Therefore, a gene, which is composed of multiple triplets in a unique
sequence, provides the code to build an entire protein, with multiple
amino acids in the proper sequence ((Figure)). The mechanism by which cells turn the DNA code into a protein product
is a two-step process, with an RNA molecule as the intermediate.
The Genetic Code
DNA holds all of the genetic information necessary to build a cell’s
proteins. The nucleotide sequence of a gene is ultimately translated
into an amino acid sequence of the gene’s corresponding protein.
From DNA to RNA: Transcription
DNA is housed within the nucleus, and protein synthesis takes place in
the cytoplasm, thus there must be some sort of intermediate messenger
that leaves the nucleus and manages protein synthesis. This intermediate
messenger is messenger RNA (mRNA), a single-stranded nucleic acid that carries a copy of the genetic
code for a single gene out of the nucleus and into the cytoplasm where
it is used to produce proteins.
There are several different types of RNA, each having different
functions in the cell. The structure of RNA is similar to DNA with a few
small exceptions. For one thing, unlike DNA, most types of RNA,
including mRNA, are single-stranded and contain no complementary strand.
Second, the ribose sugar in RNA contains an additional oxygen atom
compared with DNA. Finally, instead of the base thymine, RNA contains
the base uracil. This means that adenine will always pair up with uracil
during the protein synthesis process.
Gene expression begins with the process called transcription, which is the synthesis of a strand of mRNA that is complementary to
the gene of interest. This process is called transcription because the
mRNA is like a transcript, or copy, of the gene’s DNA code.
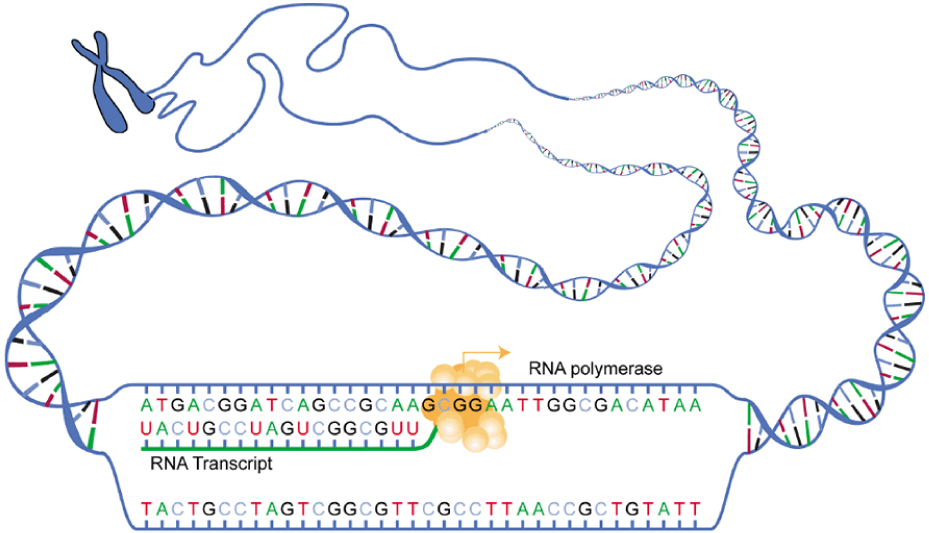
Transcription begins in a fashion somewhat like DNA replication, in that
a region of DNA unwinds and the two strands separate, however, only that
small portion of the DNA will be split apart. The triplets within the
gene on this section of the DNA molecule are used as the template to
transcribe the complementary strand of RNA ((Figure)). A codon is a three-base sequence of mRNA, so-called because they directly
encode amino acids. Like DNA replication, there are three stages to
transcription: initiation, elongation, and termination.
Transcription: from DNA to mRNA
In the first of the two stages of making protein from DNA, a gene on
the DNA molecule is transcribed into a complementary mRNA molecule.
Stage 1: Initiation. A region at the beginning of the gene called a promoter—a particular sequence of nucleotides—triggers the start of
transcription.
Stage 2: Elongation. Transcription starts when RNA polymerase unwinds the DNA segment.
One strand, referred to as the coding strand, becomes the template with
the genes to be coded. The polymerase then aligns the correct nucleic
acid (A, C, G, or U) with its complementary base on the coding strand of
DNA. RNA polymerase is an enzyme that adds new nucleotides to a growing strand of
RNA. This process builds a strand of mRNA.
Stage 3: Termination. When the polymerase has reached the end of the gene, one of three
specific triplets (UAA, UAG, or UGA) codes a “stop” signal, which
triggers the enzymes to terminate transcription and release the mRNA
transcript.
Before the mRNA molecule leaves the nucleus and proceeds to protein
synthesis, it is modified in a number of ways. For this reason, it is
often called a pre-mRNA at this stage. For example, your DNA, and thus
complementary mRNA, contains long regions called non-coding regions that
do not code for amino acids. Their function is still a mystery, but the
process called splicing removes these non-coding regions from the pre-mRNA transcript ((Figure)). A spliceosome—a structure composed of various proteins and other molecules—attaches
to the mRNA and “splices” or cuts out the non-coding regions. The
removed segment of the transcript is called an intron. The remaining exons are pasted together. An exon is a segment of RNA that remains after splicing. Interestingly,
some introns that are removed from mRNA are not always non-coding. When
different coding regions of mRNA are spliced out, different variations
of the protein will eventually result, with differences in structure and
function. This process results in a much larger variety of possible
proteins and protein functions. When the mRNA transcript is ready, it
travels out of the nucleus and into the cytoplasm.
Splicing DNA
In the nucleus, a structure called a spliceosome cuts out introns
(noncoding regions) within a pre-mRNA transcript and reconnects the
exons.
From RNA to Protein: Translation
Like translating a book from one language into another, the codons on a
strand of mRNA must be translated into the amino acid alphabet of
proteins. Translation is the process of synthesizing a chain of amino acids called
a polypeptide. Translation requires two major aids: first, a “translator,” the
molecule that will conduct the translation, and second, a substrate on
which the mRNA strand is translated into a new protein, like the
translator’s “desk.” Both of these requirements are fulfilled by other
types of RNA. The substrate on which translation takes place is the
ribosome.
Remember that many of a cell’s ribosomes are found associated with the
rough ER, and carry out the synthesis of proteins destined for the Golgi
apparatus. Ribosomal RNA (rRNA) is a type of RNA that, together with proteins, composes the
structure of the ribosome. Ribosomes exist in the cytoplasm as two
distinct components, a small and a large subunit. When an mRNA molecule
is ready to be translated, the two subunits come together and attach to
the mRNA. The ribosome provides a substrate for translation, bringing
together and aligning the mRNA molecule with the molecular “translators”
that must decipher its code.
The other major requirement for protein synthesis is the translator
molecules that physically “read” the mRNA codons. Transfer RNA (tRNA) is a type of RNA that ferries the appropriate corresponding amino
acids to the ribosome, and attaches each new amino acid to the last,
building the polypeptide chain one-by-one. Thus tRNA transfers specific
amino acids from the cytoplasm to a growing polypeptide. The tRNA
molecules must be able to recognize the codons on mRNA and match them
with the correct amino acid. The tRNA is modified for this function. On
one end of its structure is a binding site for a specific amino acid. On
the other end is a base sequence that matches the codon specifying its
particular amino acid. This sequence of three bases on the tRNA molecule
is called an anticodon. For example, a tRNA responsible for shuttling the amino acid glycine
contains a binding site for glycine on one end. On the other end it
contains an anticodon that complements the glycine codon (GGA is a codon
for glycine, and so the tRNAs anticodon would read CCU). Equipped with
its particular cargo and matching anticodon, a tRNA molecule can read
its recognized mRNA codon and bring the corresponding amino acid to the
growing chain ((Figure)).
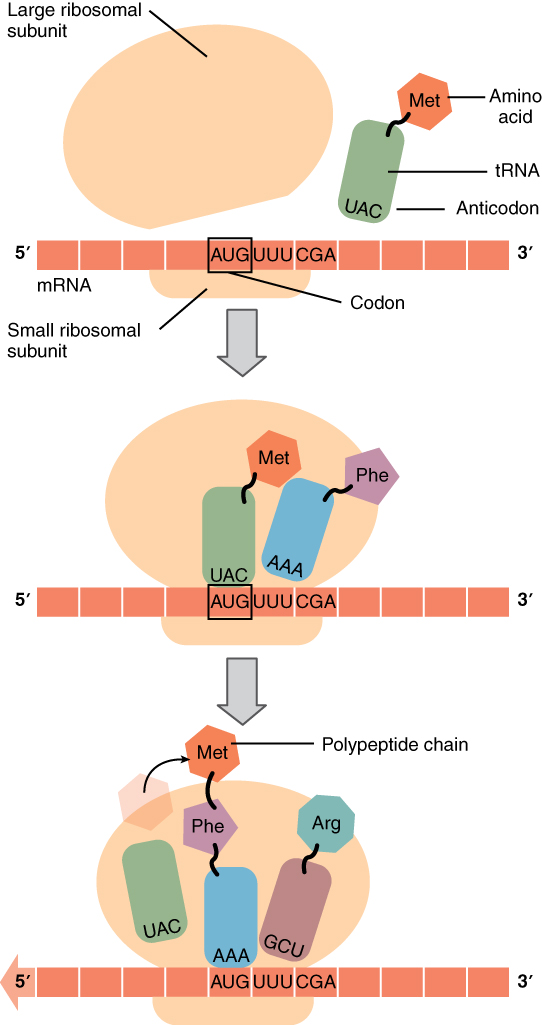
Translation from RNA to Protein
During translation, the mRNA transcript is “read” by a functional
complex consisting of the ribosome and tRNA molecules. tRNAs bring the
appropriate amino acids in sequence to the growing polypeptide chain
by matching their anti-codons with codons on the mRNA strand.
Much like the processes of DNA replication and transcription,
translation consists of three main stages: initiation, elongation, and
termination. Initiation takes place with the binding of a ribosome to an
mRNA transcript. The elongation stage involves the recognition of a tRNA
anticodon with the next mRNA codon in the sequence. Once the anticodon
and codon sequences are bound (remember, they are complementary base
pairs), the tRNA presents its amino acid cargo and the growing
polypeptide strand is attached to this next amino acid. This attachment
takes place with the assistance of various enzymes and requires energy.
The tRNA molecule then releases the mRNA strand, the mRNA strand shifts
one codon over in the ribosome, and the next appropriate tRNA arrives
with its matching anticodon. This process continues until the final
codon on the mRNA is reached which provides a “stop” message that
signals termination of translation and triggers the release of the
complete, newly synthesized protein. Thus, a gene within the DNA
molecule is transcribed into mRNA, which is then translated into a
protein product ((Figure)).
From DNA to Protein: Transcription through Translation
Transcription within the cell nucleus produces an mRNA molecule, which
is modified and then sent into the cytoplasm for translation. The
transcript is decoded into a protein with the help of a ribosome and
tRNA molecules.
Commonly, an mRNA transcription will be translated simultaneously by
several adjacent ribosomes. This increases the efficiency of protein
synthesis. A single ribosome might translate an mRNA molecule in
approximately one minute; so multiple ribosomes aboard a single
transcript could produce multiple times the number of the same protein
in the same minute. A polyribosome is a string of ribosomes translating a single mRNA strand.
Watch this video to learn about ribosomes. The ribosome binds to the mRNA
molecule to start translation of its code into a protein. What happens
to the small and large ribosomal subunits at the end of translation?
Chapter Review
DNA stores the information necessary for instructing the cell to perform
all of its functions. Cells use the genetic code stored within DNA to
build proteins, which ultimately determine the structure and function of
the cell. This genetic code lies in the particular sequence of
nucleotides that make up each gene along the DNA molecule. To “read”
this code, the cell must perform two sequential steps. In the first
step, transcription, the DNA code is converted into a RNA code. A
molecule of messenger RNA that is complementary to a specific gene is
synthesized in a process similar to DNA replication. The molecule of
mRNA provides the code to synthesize a protein. In the process of
translation, the mRNA attaches to a ribosome. Next, tRNA molecules
shuttle the appropriate amino acids to the ribosome, one-by-one, coded
by sequential triplet codons on the mRNA, until the protein is fully
synthesized. When completed, the mRNA detaches from the ribosome, and
the protein is released. Typically, multiple ribosomes attach to a
single mRNA molecule at once such that multiple proteins can be
manufactured from the mRNA concurrently.
Interactive Link Questions
Watch this video to learn about ribosomes. The ribosome binds to the mRNA
molecule to start translation of its code into a protein. What
happens to the small and large ribosomal subunits at the end of
translation?
They separate and move and are free to join translation of other
segments of mRNA.
Review Questions
Which of the following is not a difference between DNA and RNA?
DNA contains thymine whereas RNA contains uracil
DNA contains deoxyribose and RNA contains ribose
DNA contains alternating sugar-phosphate molecules whereas RNA
does not contain sugars
RNA is single stranded and DNA is double stranded
C
Transcription and translation take place in the ________ and
________, respectively.
nucleus; cytoplasm
nucleolus; nucleus
nucleolus; cytoplasm
cytoplasm; nucleus
A
How many “letters” of an RNA molecule, in sequence, does it take to
provide the code for a single amino acid?
1
2
3
4
C
Which of the following is not made out of RNA?
the carriers that shuffle amino acids to a growing polypeptide
strand
the ribosome
the messenger molecule that provides the code for protein
synthesis
the intron
B
Critical Thinking Questions
Briefly explain the similarities between transcription and DNA
replication.
Transcription and DNA replication both involve the synthesis of
nucleic acids. These processes share many common
features—particularly, the similar processes of initiation,
elongation, and termination. In both cases the DNA molecule must be
untwisted and separated, and the coding (i.e., sense) strand will be
used as a template. Also, polymerases serve to add nucleotides to
the growing DNA or mRNA strand. Both processes are signaled to
terminate when completed.
Contrast transcription and translation. Name at least three
differences between the two processes.
Transcription is really a “copy” process and translation is really
an “interpretation” process, because transcription involves copying
the DNA message into a very similar RNA message whereas translation
involves converting the RNA message into the very different amino
acid message. The two processes also differ in their location:
transcription occurs in the nucleus and translation in the
cytoplasm. The mechanisms by which the two processes are performed
are also completely different: transcription utilizes polymerase
enzymes to build mRNA whereas translation utilizes different kinds
of RNA to build protein.
Glossary
anticodon
consecutive sequence of three nucleotides on a tRNA molecule that is
complementary to a specific codon on an mRNA molecule
codon
consecutive sequence of three nucleotides on an mRNA molecule that
corresponds to a specific amino acid
exon
one of the coding regions of an mRNA molecule that remain after
splicing
gene
functional length of DNA that provides the genetic information
necessary to build a protein
gene expression
active interpretation of the information coded in a gene to produce a
functional gene product
intron
non-coding regions of a pre-mRNA transcript that may be removed during
splicing
messenger RNA (mRNA)
nucleotide molecule that serves as an intermediate in the genetic code
between DNA and protein
polypeptide
chain of amino acids linked by peptide bonds
polyribosome
simultaneous translation of a single mRNA transcript by multiple
ribosomes
promoter
region of DNA that signals transcription to begin at that site within
the gene
proteome
full complement of proteins produced by a cell (determined by the
cell’s specific gene expression)
ribosomal RNA (rRNA)
RNA that makes up the subunits of a ribosome
RNA polymerase
enzyme that unwinds DNA and then adds new nucleotides to a growing
strand of RNA for the transcription phase of protein synthesis
spliceosome
complex of enzymes that serves to splice out the introns of a pre-mRNA
transcript
splicing
the process of modifying a pre-mRNA transcript by removing certain,
typically non-coding, regions
transcription
process of producing an mRNA molecule that is complementary to a
particular gene of DNA
transfer RNA (tRNA)
molecules of RNA that serve to bring amino acids to a growing
polypeptide strand and properly place them into the sequence
translation
process of producing a protein from the nucleotide sequence code of an
mRNA transcript
triplet
consecutive sequence of three nucleotides on a DNA molecule that, when
transcribed into an mRNA codon, corresponds to a particular amino acid